
1、简述
WebTwin 是一个用 Python 编写的开源项目,用于“抓取并归档整个网站”。它能自动渲染页面、提取 HTML、CSS、JavaScript、图片、字体等资源,从而生成一个网站的“本地副本/镜像”。该工具适用于:学习网页结构与设计、分析网站资源、离线浏览、备份、用于训练 AI/机器学习模型 (对网页内容/结构进行分析),或仅作为网页开发学习的参考。
内部它主要借助下面这些技术/框架:
🔥 Python — 主代码语言。
🔥 浏览器自动化(通常用 Selenium + Chrome/Chromium) — 用于渲染现代 JS 驱动的网站,使网页 JS 执行后的最终 DOM/资源也能被抓取到。
🔥 Web 框架 Flask — 用于提供一个 Web 界面 (前端 + 后端) 让用户输入目标 URL,触发抓取流程。
因此 WebTwin 的特点是 “自动化 + 渲染 + 全资源抓取”,相比简单的 HTTP 下载 (wget/cURL) 更适合现代 SPA/JS-heavy 网站。

2、如何安装 WebTwin
下面是一个典型的安装/配置流程 (假设在 Linux 或 macOS 下;Windows 下类似,只是激活虚拟环境方式略不同) — 基于项目官方/社区文档。
克隆项目
git clone https://github.com/sirioberati/WebTwin.git
cd WebTwin
创建并激活 Python 虚拟环境
python -m venv venv
source venv/bin/activate # macOS / Linux
# Windows 则是 venv\Scripts\activate
安装依赖
pip install -r requirements.txt
(可选) 安装浏览器 + 对应 webdriver
🔥 安装 Chrome 或 Chromium 浏览器
🔥 安装对应版本的 ChromeDriver(或其他 webdriver),确保 Selenium 能正常启动浏览器
启动 WebTwin 服务
python app.py
打开浏览器访问
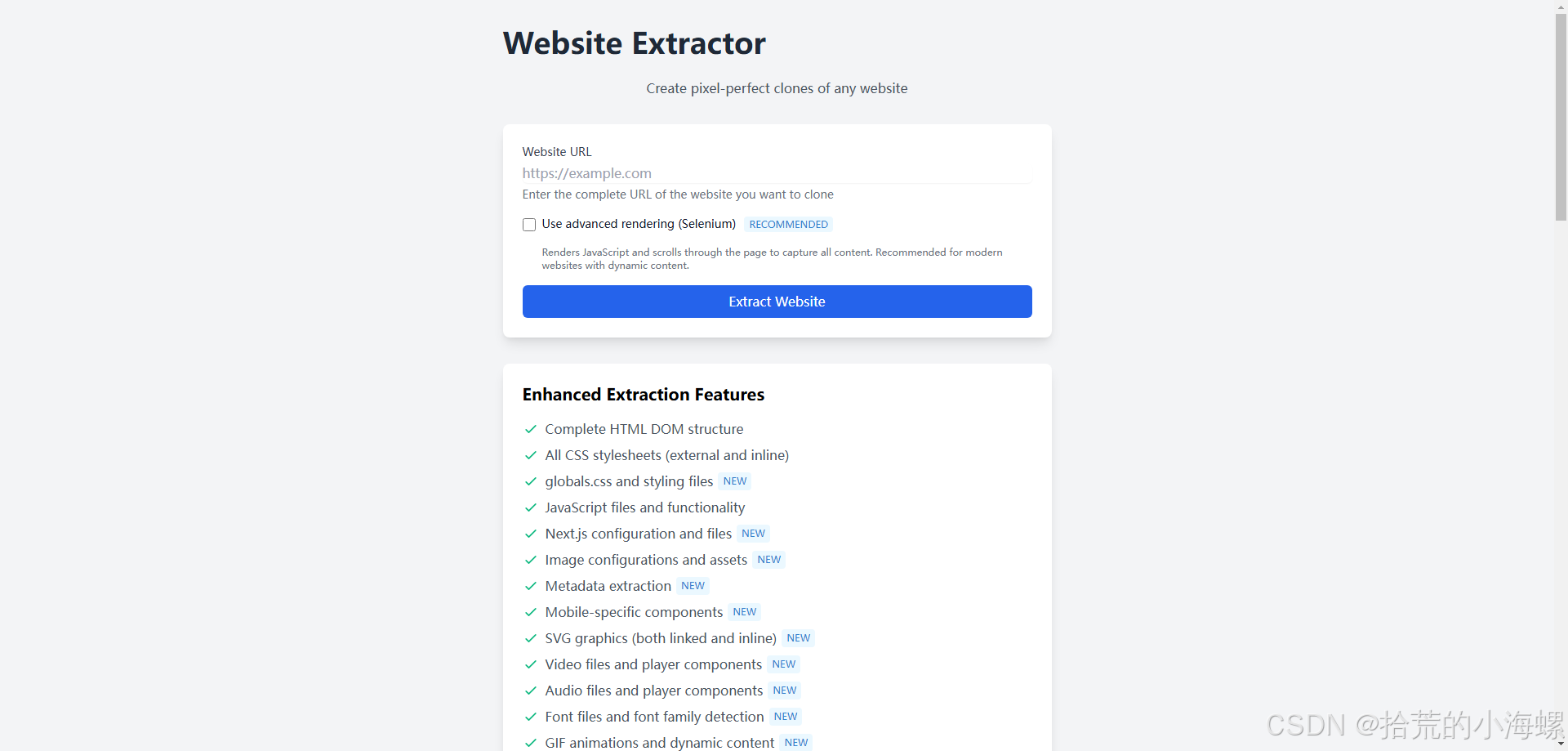
通常访问 http://127.0.0.1:5001 (或配置中的 host/port),在界面中输入你希望抓取的网址 (URL),选择是否启用“高级渲染”(rendered JS),然后点击“提取网站 / Extract site”按钮即可。
执行成功后,你将在本地得到一个静态网站副本 (包含 HTML、CSS、JS、图片等),方便离线查看或进一步分析。
3、WebTwin 项目结构 (目录说明)
典型项目文件/目录结构如下 (基于社区文档) :
WebTwin/
├── docs/ # 文档/说明资料
├── templates/ # Flask 用的 HTML 模板 (前端界面)
├── .gitignore # Git 忽略配置
├── LICENSE # 许可证
├── README.md # 项目介绍
├── app.py # 主程序,启动 Flask Web 服务
├── app_architecture.md# 架构说明文档
├── requirements.txt # Python 依赖列表
└── setup.py # 项目安装/打包脚本(如有)
🔥 templates/ 下是用于 Web 界面的模板 (例如 index.html);用户通过这个界面提交抓取任务。
🔥 docs/ 可能包含使用指南、贡献指南、开发文档等。
4、实践样例
下面是一个 “从零开始使用 WebTwin 抓取某个网站” 的示例 (假设目标 site 为 https://example.com):
🔥 安装并启动 (按前面“安装”步骤执行),确保服务运行在 http://127.0.0.1:5001。
🔥 访问 Web 界面 — 在浏览器中打开 http://127.0.0.1:5001,你会看到一个简单的输入框 (URL) + 选项 (是否启用高级渲染) + “提取 / Extract”按钮。
🔥 输入目标 URL:填写 https://example.com,选择 “启用高级渲染 (render JS)” (如果该网站使用了 JavaScript 动态内容),点击 “提取网站 / Extract site”。
🔥 等待抓取完成 — WebTwin 会启动一个 headless 浏览器 (Chrome/Chromium),加载页面 (包括运行 JS)、下载页面所有资源 (HTML / JS / CSS / 图片 / 字体 /静态资源),并将它们保存到本地。
🔥 查看结果 — 抓取成功后,会在本地生成一个静态副本 (文件夹),你可以用文件浏览器或者直接启动本地静态服务器 (例如 python -m http.server) 来查看这个静态网站,就像原网站一样 (或非常接近)。
🔥 离线分析 / 学习 / 备份 /复用 — 你可以查看网页源码、资源结构、CSS/JS 分析,也可以用于网页设计学习,或者离线备份 / 迁移 / 用作数据输入 (例如将静态页面作为训练/分析语料) 等。
4.1 WebTwin 的典型应用场景
🔥 网页备份 / 归档:对重要网站 (博客、文档站、公司官网等) 做完整备份,方便离线查看或防止网站失联。
🔥 网页结构/资源学习:对优秀网站进行 “拆解”:分析 HTML 结构、CSS、JS、静态资源组织方式等,是学习前端/网页设计/页面优化的好方式。
🔥 离线浏览/迁移:将网站完整抓取到本地,用于脱网环境展示/迁移/存档。
🔥 数据收集 / 训练语料:将网页静态化后,可用于构建网页内容语料库 (如用于机器学习、自然语言处理、页面解析、网页分类等用途)。
🔥 安全/审计/测试:在本地审查网页资源、分析 JS 行为、检查外部依赖、静态化快照用于审计或渗透测试 (当然需合法合规)。
4.2 注意事项与限制
🔥 如果目标网站有 反爬 / 反自动化机制 (如动态验证码、IP 限制、反机器人机制、请求频率限制等),WebTwin 的自动抓取可能失败或导致被封禁。
🔥 对 大型/复杂网站 (多页面、动态加载、懒加载、前后端分离、API 数据请求、异步渲染等),抓取可能不完整 — 例如某些资源可能由 XHR/Ajax 动态加载,WebTwin 未必捕捉到所有请求/资源。
🔥 版权 / 法律风险:抓取网站资源可能涉及版权/隐私/使用条款问题。请遵守目标网站的 robots.txt / 使用协议 / 法律法规,仅在合法/授权/合理使用 (研究、备份、自用) 的前提下使用。
🔥 抓取大量网页资源 (大网站) 时,可能对本地存储和带宽造成压力。
5、总结
WebTwin 是一个非常实用、轻量的 “网站静态化 / 归档 / 抓取” 工具,通过自动渲染 + 自动下载资源,实现对现代 JS 网站的完整提取。对于想要备份网站、离线浏览、学习网页设计、分析网页结构或制作网页语料库的人来说,是一个很好的起点。
